
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- AIDEEPDIVE
- 혁펜하임
- 혁펜하임AI
- 백준 Σ
- mysql
- 자료구조
- 백준 시그마 파이썬
- 백준 구간 합 구하기 5 파이썬
- 다이나익 프로그래밍
- 분할 정복을 이용한 거듭제곱
- 알고리즘
- 다이나믹프로그래밍
- 코딩테스트
- 수학
- 백준 Σ 파이썬
- 백준 시그마
- AI강의
- 패스트캠퍼스혁펜하임
- 혁펜하임강의후기
- 백준 구간 합 구하기 5
- 패스트캠퍼스
- 혁펜하임강의
- 백준 13172
- DP
- 분할 정복
- 백준 13172 파이썬
- 큐
- 그리디알고리즘
- 모듈로 곱셈 역원
- 구현
- Today
- Total
MingyuPark
가중치 초기화 / optimizer 본문
서론
딥러닝 모델을 잘 학습시키기 위해서는 해당 모델의 가중치(w)를 잘 학습하는 게 가장 중요하다.
가중치는 입력신호가 출력에 얼마나 영향을 주는지를 나타내는 값이며,
딥러닝 모델을 잘 학습시킨다는 것은 가중치를 잘 학습시키는 것과 동일한 의미를 갖는다.
이러한 가중치를 어떻게 초기화하며 어떻게 최적화를 해야 하는지에 대해 정리해보았다.
본론
1. 가중치 초기화
가중치를 최적화하려면 최적화할 가중치가 존재해야 한다. 그러면 그 가중치는 어떻게 구해야 할까.

정답 : 0 근처의 값으로 초기화한다.
그러면 그냥 내 마음대로 값을 주면 된다. 절대 아니고 초기화하기 위한 다양한 방법이 제시되어있다.
신경망이 사용하는 activation function에 따라 다양한 초기화 방법이 제시되어 있다.
Uniform 분포 또는 정규분포를 사용한다. (평균과 분산이 같은)
- X∼U(a,b)일 때, E(X)=a+b2, Var(X)=(b−a)212 이라는 사실을 이용하면 두 분포가 평균과 분산이 같다는 것을 쉽게 보일 수 있다.
- 각 activation function에 맞게 적절히 사용하면 될 것 같다.
2. 가중치 최적화
가중치 최적화 방법에 대해 정리하기 전에 존재하는 optimizer들을 정리해놓고 어떤 식으로 변형되면서 만들어졌는지 알기 쉽게 요약해놓은 사진이 있어서 가져왔다.
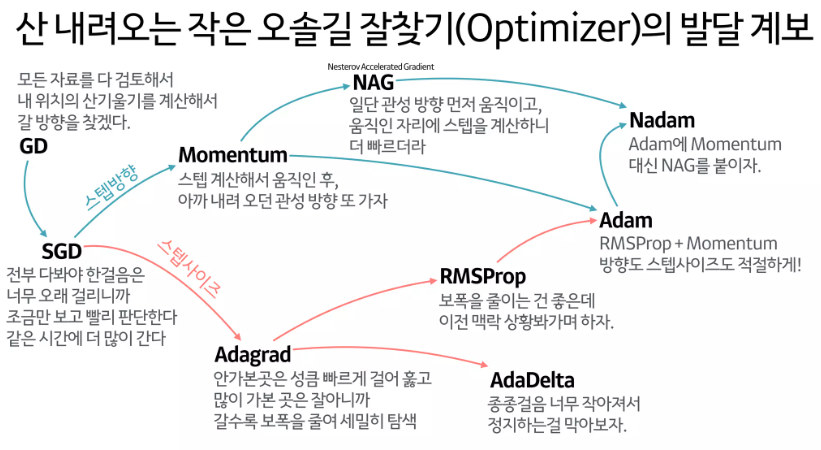
이번 포스팅에서는(AI deep dive 강의에서는) Gradient descent, stochastic gradient descent, momentum, RMSProp, Adam에 초점을 맞춰서 내용을 정리해보았다.
1) Gradient descent : 모든 데이터를 이용해서 최적화
가장 기본적인 형태의 최적화 방법이다. 가중치 a,b가 존재한다고 했을 때, 기울기가 가장 가파른 방향으로 조금씩 이동하면서 최적점에 도달하는 방법이다.
[ak+1bk+1]=[akbk]−α[∂L∂a∂L∂b]a=akb=bk
모든 데이터를 활용하기 때문에 최적점을 향해서 정확히 나아갈 수 있지만, 모든 데이터를 활용하기 때문에 시간이 오래 걸린다는 단점도 존재한다.
조금만 보고 빨리 판단해서 같은 시간에 더 많이 이동하면 시간을 아낄 수 있을 것이다.
2) Stochastic gradient descent : 데이터를 하나씩만 이용해서 최적화
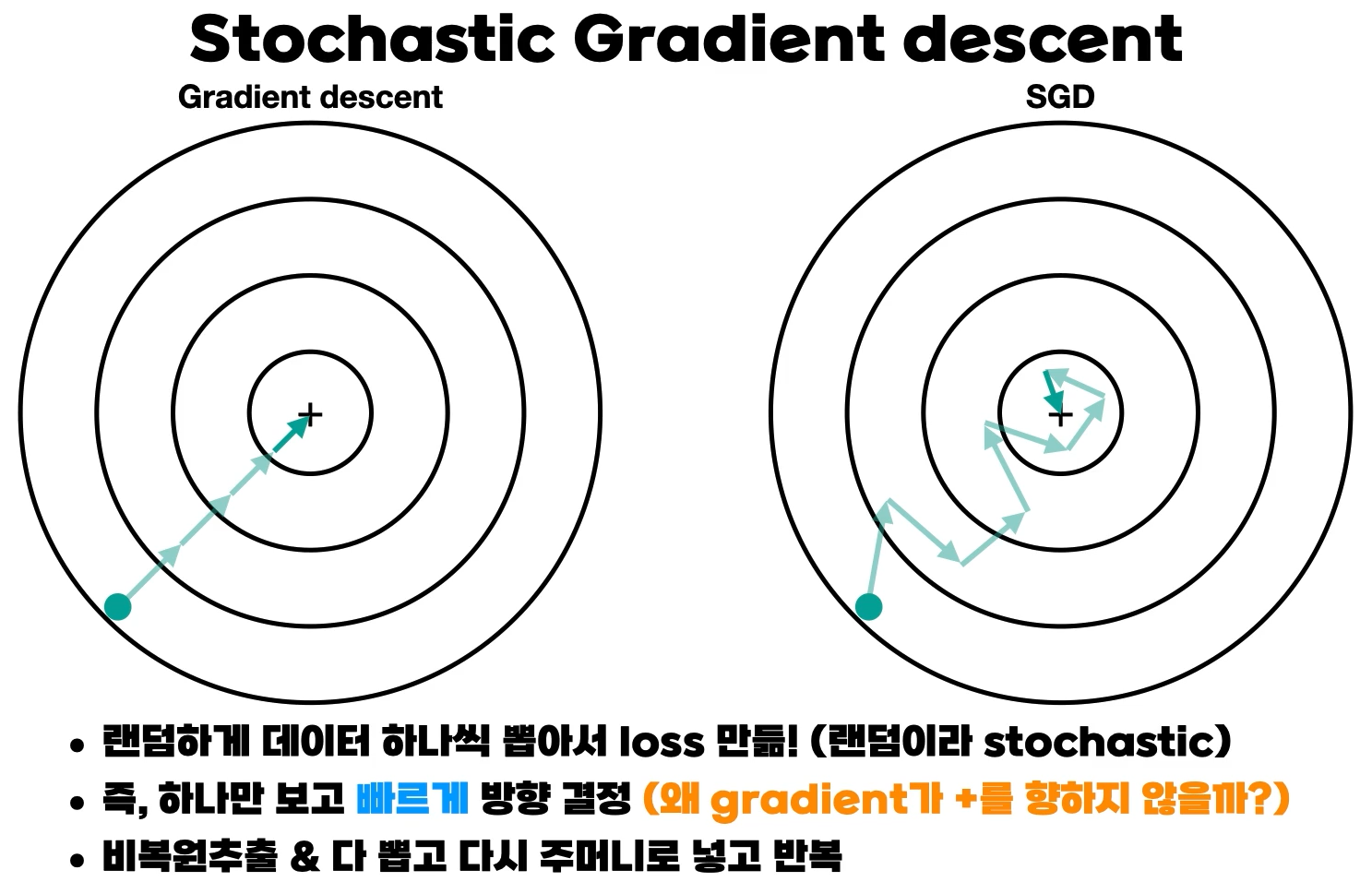
GD는 4 step, SGD는 8 step이라서 SGD가 더 비효율적인 것처럼 보일 수 있지만 SGD는 데이터를 하나만 보기 때문에 한 step이 훨씬 빠르다. 또한 GD와 다르게 곧은 방향이 아니라 여기저기 움직이면서 다니기 때문에, 위 그림의 '+'가 local minima였고, global minima가 다른 곳에 존재한다면 오히려 그 쪽으로 갈 기회도 생길 수 있다.(물론 무조건 local minima에서 탈출할 수 있다고는 할 수 없음.)
하나의 데이터만 보고 이동하는 것이 빠르긴 한데, 이 방법이 가장 효율적이라고 할 수 있을까?
3) Mini-batch SGD : 여러 개의 데이터를 이용해서 최적화
전부 다 보면서 이동하는 것은 너무 느리고, 하나만 보는 것은 너무 성급한 것 같다.

그래서 조금만 쓰자. -> mini-batch SGD
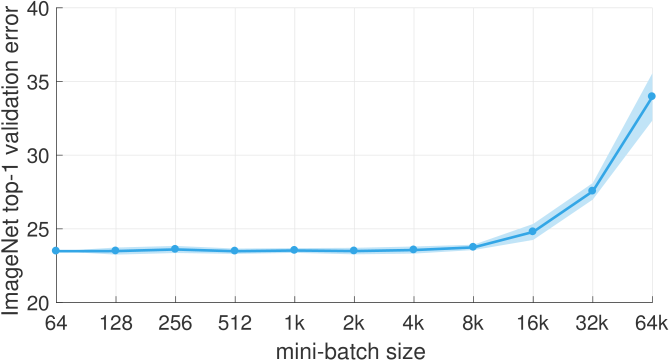
GPU를 이용해서 병렬 연산을 수행하면 속도도 빠르다. 그렇다고 batch size를 무작정 늘리면 안된다고 한다.
아래 그림과 같이 Batch size가 8K를 넘어가게 되면 error가 증가한다.
4) Momentum
말 그대로 관성을 이용한 최적화 방법이다. 진행하던 속도에 관성을 주는 것이다.
같은 방향으로 진행하고 있으면 가속이 붙어서 점점 더 빠르게 간다. 이렇게 되면, 작은 언덕(local minima) 정도는 그냥 건너뛰고 지나갈 수 있게 된다.
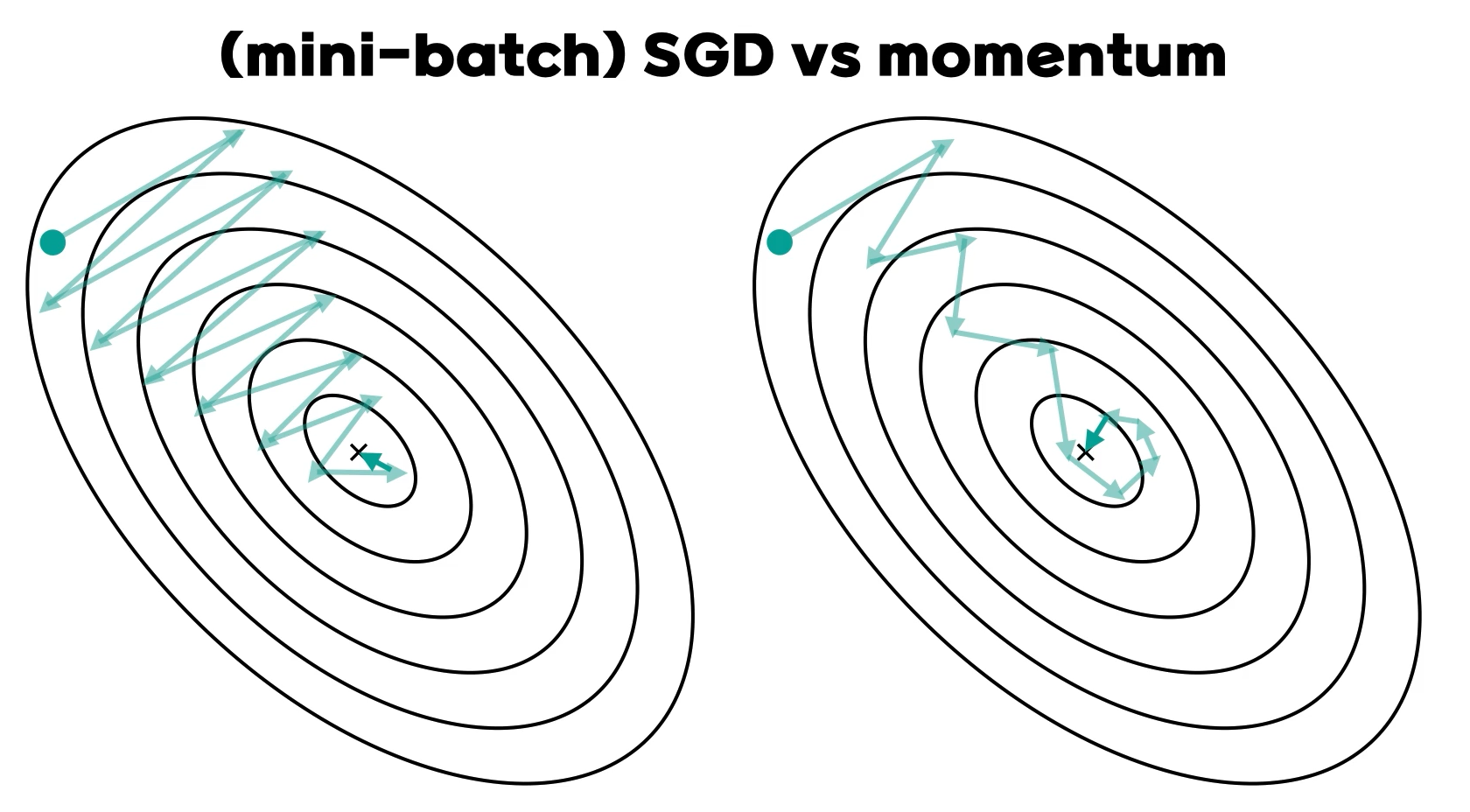
이전의 gradient들을 고려해서 관성을 주는데, 그대로 남아있으면 평지에서도 끝없이 진행할 수 있기 때문에 마찰계수를 이용해서 이전 gradient들의 영향력을 매 업데이트마다 γ배씩 감소시킨다.
vt=γvt−1+η∇θtJ(θt)θt+1=θt−vt
- η∇θtJ(θt)=gt라고 하고, v1=g1이라고 하자.
- v2=γv1+g2=γg1+g2
- v3=γv2+g3=γ2g1+γg2+g3
- ...
5) RMSProp
RMSProp은 과거의 gradient를 제곱해서 더하는 방식으로 학습을 진행하는 AdaGrad의 단점을 보완하기 위한 방식이다.
학습을 거듭하다보면 갱신량이 0이 되어 갱신되지 않는 문제가 발생하는데, RMSProp은 과거의 기울기에 대해서 가까운 과거의 기울기를 더 많이 반영하고, 먼 과거의 기울기를 조금만 반영한다.
6) Adam ( Adaptive Moment Estimation)
RMSProp과 Momentum을 융합한 방식이다.

1) 본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
2) 강의 링크 : https://bit.ly/3GV73FN
'Deep learning' 카테고리의 다른 글
| 이진 분류와 다중 분류 - AI DEEP DIVE 후기 (0) | 2023.02.07 |
|---|---|
| MLP, Backpropagation - AI DEEP DIVE 후기 (0) | 2023.02.06 |

